Treinando sua primeira rede neural para uma tarefa de classficação simples
Olá, seja bem vindo(a) a mais um tópico na série de estudo sobre Tensorflow. Finalmente, iremos colocar a mão no massa e codificar nossa primeira rede neural para uma tarefa de classificação simples. Espero que você já tenha preparado seu ambiente para rodar os scripts, senão, confira os links ao final do post e siga a opção desejada. Antes de continuar, você precisa estar familiarizado com os conceitos de aprendizado de máquina. Uma boa referência é o machine learning crash course produzido pela google.
O objetivo deste post é treinar um modelo de rede neural para classificar images de vestuário, tais como tênis e camisas. Ao terminar a leitura, você será capaz de:
- carregar o conjunto Fashion Mnist como dados de treinamento
- explorar e preprocessar os dados de treinamento
- construir seu modelo com o TensorFlow
- treinar, avaliar e fazer predições com seu modelo.
Importando pacotes necessários
Vamos usar o pacote tf.keras, uma api de alto nível do TensorFlow para construir e treinar o modelo.
O trecho do código a seguir importa os pacotes necessários para nosso script rodar tranquilamente.
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
1.11.0
Carregando o conjunto de dados Fashion Mnist.
O conjunto de dados Fashion Mnist contém 70.000 imagens em tons de cinza divididas em 10 categorias.
As imagens mostram itens de vestuário em baixa resolução (28 por 28 pixels), como pode ser observado abaixo:
![]()
Figura 1. Conjunto de dados Fashion-MNIST (by Zalando, MIT License).
O Fashion Mnist é uma alternativa ao conjunto de dados Mnist, muito utilizado como um “Olá, mundo” para programas de aprendizado de máquina em visão computacional. Ambos são relativamente pequenos, perfeitos para verificar se um algoritmo funciona adequadamente e servem como bons pontos de partida para testar e debugar seu código.
Vamos dividir o Fashion Mnist em duas partes. A primeira parte irá conter 60.000 images que será utilizada para treino e a outra parte irá conter 10.000 images que será utilizada para teste e avaliar o desempenho de nosso modelo, ou seja, o quão bom nosso modelo é para classificar as imagens. Você pode carregar o Fashion Mnist diretamente pelo TensorFlow, apenas importando e carregando os dados:
# import data
fashion_mnist = keras.datasets.fashion_mnist
# load data
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 1s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
Ao carregar os dados, quatro arrays Numpy são retornados:
train_imagesetrain_labelssão os conjuntos separados para treino.test_images,test_labelssão o conjuntos de dados separados para teste.
Nota que o procedimento de dividir os dados em conjunto de treino e teste foi feito automaticamente ao importar e carregar o Fashion Mnist. Isso facilita muito o processo de aprendizagem, porém, não acontece no mundo real. Quando estiver trabalhando com sua própria base, você terá que fazer isso manualmente.
As imagens são formadas por arrays Numpy com o formato 28 x 28 pixels com valores variando de 0 a 255 representando a escala de cinza. Os rótulos (labels) são arrays de inteiros variando de 0 a 9 representando os tipos de vestuário. A tabela a seguir mostra a relação entre o rótulo e o tipo (Class) de imagem.
| Labels | Class |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
Precisamos armazenar o nome das classes em um vetor para utilização posterior quando plotarmos as imagens em um gráfico, um vez que esses nomes não estão disponíveis no conjunto de dados.
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Explorando os dados
A seguir serão mostrados alguns comandos úteis antes de sair treinando o modelo, para que você possa ter certeza dos dados que você tem em mãos. Use os comandos print, shape e len para conhecer os seus dados em detalhes. O primeiro, imprime algo na tela do computador, o segundo retorna o formato do array, e o terceiro retorna o comprimento de um array.
print(train_images.shape)
# (60000, 28, 28)
print(len(train_images))
# 60000
print(train_labels)
# array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
print(test_images.shape)
# (10000, 28, 28)
print(len(test_images))
# 10000
print(test_images)
# array([9, 8, 0, ..., 3, 2, 5], dtype=uint8)
Preprocessamento de dados
Os dados precisam ser preprocessados, isto é, preparados adequadamente antes de treinar o modelo. Se você observar a primeira imagem do conjunto de treino usando o código a seguir, você verá que os valores dos pixels variam de 0 a 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
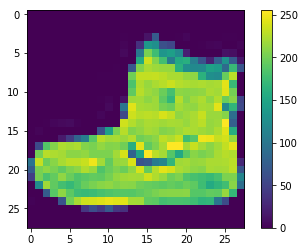
Nós precisamos reduzir esse valor para uma variação que permanece entre 0 e 1 para que a nosso modelo, que será baseado em rede neural, possa conseguir extrair algum padrão dos dados. Para tanto, basta dividirmos o valor atual de cada pixel pelo valor máximo disponível que é de 255.0.
É importante os dados de treino e de teste sejam preprocessados da mesma maneira:
train_images = train_images / 255.0
test_images = test_images / 255.0
Para mostrar as 25 primeiras imagens com a sua respectiva legenda crie um laço e use os métodos subplot, imshow e xlabel do pacote matplotlib.pyplot. Observe que as imagens estão no formato correto e isso significa que estamos prontos para criar e treinar nosso modelo.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])

Construindo o modelo
O processo de criação de um modelo baseado em rede neural consiste basicamente de dois passos: configuração das camadas, e compilar o modelo.
Configuração das camadas
Uma rede neural artificial é formado por um conjunto de camadas. Essas camadas extraem representações dos dados de entrada que tendem a ser mais significativas para a resolução do problema.
A maioria dos modelos em aprendizado profundo consiste no encadeamento de várias camadas simples. Um exemplo é o encadeamento de camadas do tipo tf.keras.layers.Dense que possuem neurônios que são atualizados durante o treinamento.
Você pode construir um encadeamento de camadas usando o módulo keras.Sequential e passar as camadas desejadas como argumento:
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
A primeira camada nesta rede é do tipo tf.keras.layers.Flatten, que tem o objetivo de achatar um array-2d em um array-1d. Nesse caso particular, iremos achatar uma imagem de 28x28 pixels em um vetor de 784 posições, representando 28 x 28 = 784 pixels. Na prática, essa camada pega cada linha de pixels em uma imagem e coloca umas sobre as outras. É importante ressaltar que essa camada não possui nenhum parâmetro para aprender, apenas formata uma imagem adequadamente para ser processada por uma camada do tipo tf.keras.layers.Dense .
Após os pixels serem achatados, o nosso modelo encadea duas camadas tf.keras.layers.Dense. Como o próprio nome sugere, são camadas densamente conectadas onde cada neurônio se conecta a uma entrada, e cada entrada se conecta a um neurônio. O termo totalmente conectadas também é usada para descrever o mesmo conceito. A primeira camada Dense possui 128 neurônios. A segunda (e ultima) camada possui 10 neurônios e usa a função softmax como ativação. Portanto, a ultima camada retorna um placar com 10 valores de probabilidade que totalizam 1. Assim, cada neurônio contem um placar de 0 a 1, indicando a probabilidade de que a imagem atual pertença a uma das 10 classes de vestuário.
Compilando o modelo.
Após configurar sua rede, ainda é necessário fazer alguns ajustes antes de iniciar o treinamento. Esses ajustes são adicionados na fase de compilação do modelo:
- Função custo - Responsável por medir quão preciso o modelo é durante o treino. O objetivo do treino é minimizar o função custo para orientar o modelo na direção correta.
- Otimizador - Respnsável por dizer como o modelo é atualizado com base nos dados e na função custo.
- Metricas - Utilizado para monitorar as fases de treino e de teste. O seguinte exemplo usa
accuracycomo opção de métrica. Aaccuracyou acurácia irá indicar o percentual das imagens que foram classificadas corretamente.
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Treinando o modelo
Primeiro, temos que alimentar o modelo com os dados de treino. Nesse exemplo, armazenamos essas dados nas variáveis train_images e train_labels. O modelo então, tentar aprender a associar cada imagem com um rótulo. Uma vez que o modelo foi treinado, podemos perguntar a ele a respeito de um conjunto de dados que ele ainda não viu, que são os dados de teste, e nesse exemplo, usamos a variável test_images e seus respectivos rótulos armazenados em test_labels.
Para iniciar um treinamento, basta chamar o método model.fit passando os dados de treino e o número de épocas a serem treinadas.
model.fit(train_images, train_labels, epochs=5)
Epoch 1/5
60000/60000 [==============================] - 5s 82us/step - loss: 0.5024 - acc: 0.8235
Epoch 2/5
60000/60000 [==============================] - 5s 77us/step - loss: 0.3765 - acc: 0.8633
Epoch 3/5
60000/60000 [==============================] - 5s 80us/step - loss: 0.3382 - acc: 0.8762
Epoch 4/5
60000/60000 [==============================] - 5s 76us/step - loss: 0.3154 - acc: 0.8847
Epoch 5/5
60000/60000 [==============================] - 5s 78us/step - loss: 0.2958 - acc: 0.8912
Note que quando o treino inicia, o custo e a métrica são apresentados na saída do terminal. No final do treinamento, esse modelo atinge uma acurácia de 0.88, ou seja, 88% de acertos na classificação das imagens de vestuário em uma das das classes disponíveis em relação aos dados de treino. Porém, o número que realmente importa é em relação aos dados de teste.
Avaliação da acurácia
Para avaliar se seu modelo realmente é bom, você pode utilizar o método model.evaluate e passar como argumento os dados de teste.
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
10000/10000 [==============================] - 1s 50us/step
Test accuracy: 0.8732
Observe que a precisão no conjunto de dados de teste é um pouco menor que a precisão no conjunto de dados de treinamento. Essa lacuna entre a precisão do treinamento e a precisão do teste é um exemplo de overfitting. O overfitting é quando um modelo de aprendizado de máquina apresenta um desempenho pior em novos dados do que em seus dados de treinamento. Você deve evitar overfitting com uma diferença muito grande entre treino e teste.
Usando o modelo
Uma vez treinado, o modelo pode fazer predição, isto é, classificação sobre novas imagens.
predictions = model.predict(test_images)
O método model.predict faz predições do rótulo sobre cada imagem no conjunto de teste. Se imprimirmos a predição sobre a primeira imagem nesse conjunto nos temos na sáida 10 valores de probabilidade correspondentes a cada classe, como explicado anteriormente.
predictions[0]
array([1.0268966e-05, 4.5652584e-07, 2.2796411e-07, 2.6025206e-09,
4.2522177e-07, 4.1701975e-03, 1.1740666e-05, 2.8226489e-02,
4.3704877e-06, 9.6757573e-01], dtype=float32)
Se você estiver usando um jupyter notebook, não precisa utilizar a função print quando quiser imprimir na tela o resultado de um instrução simples.
Para visualizar o rótulo que tem a maior probabilidade nos valores de predições, utilize o método argmax do pacote Numpy:
print('Imagem predito: {} - {}'.format(np.argmax(predictions[0], class_names[np.argmax(predictions[0]]) ))
print('Imagem real: {} - {}'.format(test_labels[0], class_names[test_labels[0]]))
Imagem predita: 9 - ankle boot
Imagem real: 9 - ankle boot
Note que para essa amostra o modelo acertou o valor do rótulo da imagem.
Podemos fazer um gráfico para ver o conjunto completo das 10 classes.
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Vamos utilizar essas duas funções para observar as imagens de índice 0 e 12 nos dados de teste.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)

i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)

Agora vamos plotar várias imagens e suas respectivas predições. Rótolos com predições corretas estão em azul e prdições incorretas estão na cor vermelha. O número dá a porcentagem (de 0 a 100) para cada classe predita.
# Plot the first X test images, their predicted label, and the true label
# Color correct predictions in blue, incorrect predictions in red
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)

Para finalizar, vamos usar nosso modelo para fazer predição de uma única imagem. Observe que, anteriormente, nós tinhamos feito a predição em todo o conjunto de teste.
# Grab an image from the test dataset
img = test_images[0]
print(img.shape)
(28,28)
tf.keras models é otimizado para fazer predições em uma sequência de dados, ou em lote. Então, como estamos usando uma única imagem, precisamos adicioná-la em uma lista usando o método expand_dims do pacote Numpy.
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1,28,28)
Agora, fazendo a predição:
predictions_single = model.predict(img)
print(predictions_single)
[[1.0268966e-05 4.5652627e-07 2.2796455e-07 2.6025206e-09 4.2522097e-07
4.1701999e-03 1.1740666e-05 2.8226525e-02 4.3704831e-06 9.6757573e-01]]
plot_value_array(0, predictions_single, test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)

É importante mencionar que o método model.pridict retorna uma lista de listas, uma para cada image nos lotes de dados. Então, para obter a predição para nossa única imagem é preciso indicar o índice 0, pois os arrays em python iniciam do 0.
np.argmax(predictions_single[0])
9
#@title MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.
Resumo
Neste post, você acompanhou o passo a passo de como criar e treinar seu primeiro modelo de aprendizado de máquina para classificar uma base de dados de vestuário utilizando o biblioteca de alto nível Keras que acompanha o TensorFlow. Os tópicos que você aprendeu foram:
- Como explorar seu conjunto de dados de modo que você tenha um entendimento melhor dos dados que você tem em mãos para treinar seu modelo
- Como configurar e compilar seu modelo usando a API de alto nível Keras disponível no TensorFlow
- Como visualizar os resultados obtidos através de gráficos usando o pacote
matplotlib.pyplot
Agradecemos sua visita, e desejamos que tenham gostado do post e que ele possa ter contribuído de alguma forma para sua carreira. Se ficou com alguma dúvida sobre como treinar sua primeira rede neural com o TensorFlow, utilize o espaço reservado para comentários abaixo. Se esse conteúdo foi útili para você, com uma linguagem clara e objetiva, ajude-nos a compartilhar com outras pessoas.
- Como ver o que nunca foi visto
- 2021 e as tecnologias pós-pandemia.
- Como é a rotina de um engenheiro da computação?
- Software customizado x Software não-customizado
- Sobre o desafio dos #100DaysOfCode.
- Sete curiosidades sobre Ada Lovelace.
- Como prever o valor de venda de uma casa?
- Como fazer classificação binária de textos
- Treinando sua primeira rede neural para uma tarefa de classficação simples
- Instalando o Tensorflow no Raspbian
- Instalando o Tensorflow no Windows
- Instalando o Tensorflow no macOs
- Instalando o Tensorflow no Ubuntu
- Instalando o Tensorflow - apresentação
- Bem vindo(a) ao Tensorflow!